With video making up more and more of the media we interact with and create daily, there is a growing need to track and index that content. What meeting or seminar was it where I asked that question? Which lecture dealt with tax policies? A machine learning solution from Twelve Labs could make it easier for consumers and creators to find and watch video.
The startup can put in a complex yet vague query and instantly get the video of the office party where the national anthem was sung. That command-F is for our friends on Macs.
You might think I can't find the video you're looking for, but I can find it on the internet. What happens after that? You can either look through the video for the part you're looking for, or look through the transcript for the exact way they said it.
When you search for video, you are looking for tags, descriptions and other basic elements that can be easily added at scale. The system doesn't really understand the video itself, but there is some algorithmic magic that can be used to surface the video you want.
The industry has oversimplified the problem, thinking tags can solve it. Some frames of the video contain cats, so it adds the tag #cats. We knew we needed to build a new neural network that could take in both visual and audio information, and that it was called multimodal understanding.
We seem to be reaching limits in how well an artificial intelligence system can comprehend the world when it is focused on one thing. An artificial intelligence that paid attention to both the imagery and text in a post at the same time was needed by Facebook.
If you're looking at individual frames and trying to draw associations with a time stamped transcript, your understanding will be limited. When people watch a video, they use the video and audio information to create their own personas, actions, intentions, cause and effect, interactions and other more sophisticated concepts.
The video understanding system built by Twelve Labs is similar to these lines. Lee explained that the artificial intelligence was trained to approach video from a multi-dimensional perspective, to associate audio and video from the start, and to create what they say is a much richer understanding of it.

The animation shows a sample query. The image is from Twelve Labs.
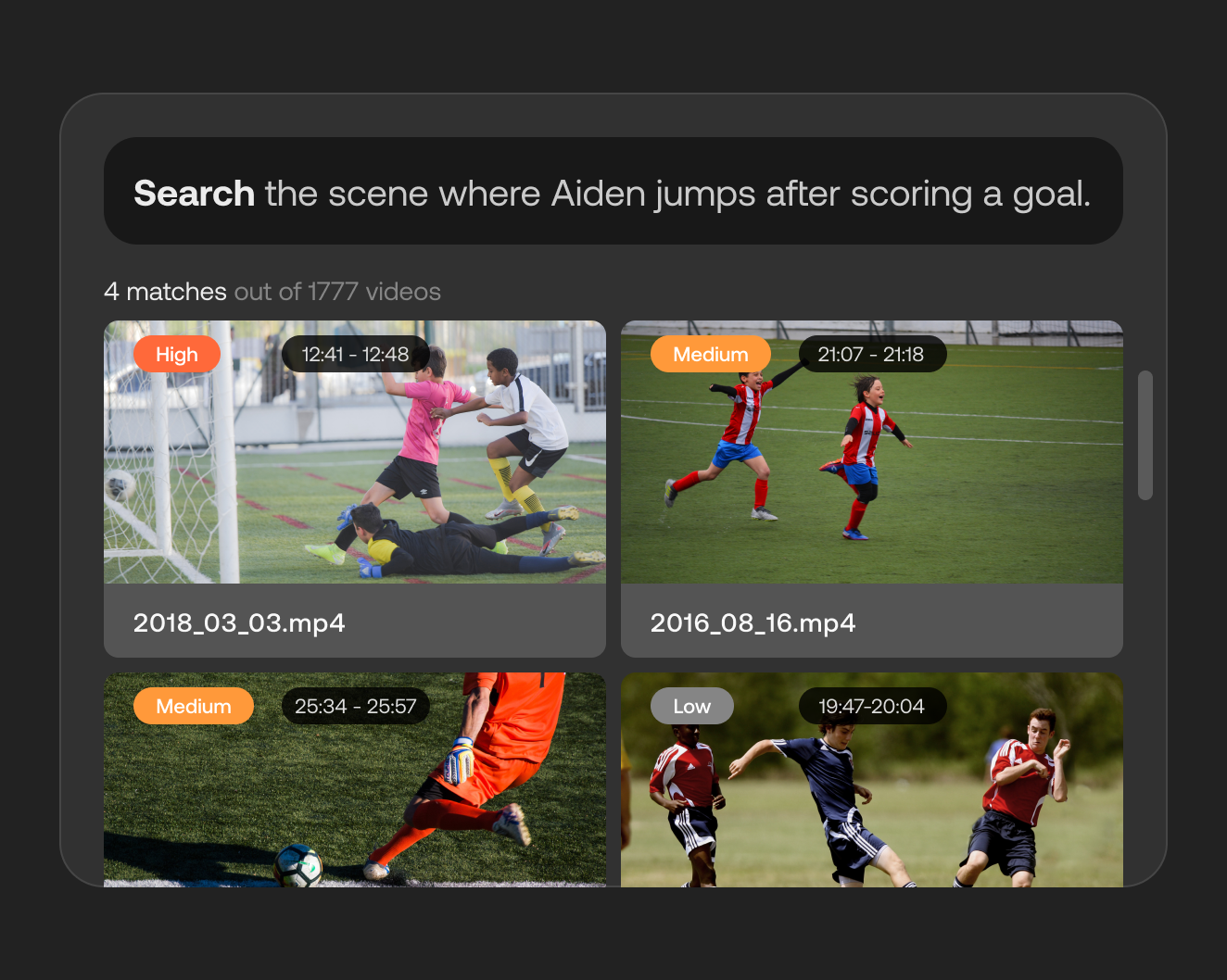
It's possible to do complex queries with more complex information like relationships between items in the frame.
Mr Beast may have put that in the title or tags, but what if it is just part of a regular vlog or a series of challenges? What if Mr Beast didn't fill in all the information correctly because he was tired? If there are a dozen burger challenges, and a video search can tell the difference between Joey Chestnut and Josie Acorn, what should we do? It can fail you if you are leaning on a superficial understanding of the content. If you're a corporation looking to make 10,000 videos searchable, you want something better and less labor intensive than what's out there.
Twelve Labs built a tool that can be called to index a video and generate a rich summary and connect it to a chosen graph. If you record all-hands meetings, skill-share seminars, and weekly brainstorming sessions, they will become searchable by who talks, when, and what, as well as other actions like drawing a diagram or showing slides.
Lee said that companies with lots of organizational data are interested in finding out when the CEO is talking about or presenting a certain concept.
The image is from Twelve Labs.
The ability to generate summaries and caption is a side effect of processing a video for search. Things could be improved in this area. The quality of the auto-generated caption, as well as the ability to search them, attach them to people and situations in the video and other more complex capabilities, vary widely. A high-level summary is valuable for everything from accessibility to archival purposes, and it's a field that's taking off everywhere.
It can be fine-tuned to better work with the corpus it is being unleashed on. If there is a lot of jargon or a few unfamiliar situations, it can be trained to work in those situations as well as it would with more commonplace situations. Before you get into things like college lectures, security footage, and cooking.

The model should work better with salad-related content. The image is from Twelve Labs.
The company is very much in favor of the big network style of machine learning. Making an artificial intelligence model that can understand complex data and produce a variety of results is a lot of work. Lee said that is what is needed for this problem.
He said that they don't just increase the size of the network. We don't look at every frame and use a light algorithm to identify important frames. There is still a lot of science to be done in language understanding. The purpose of a large network is to learn the statistical representation of the data that has been fed into it.
There is no Twelve Labs web platform that allows you to search for stuff, so you won't be aware of it. The results will be way better if the API is integrated into existing tech stacks. This has been shown in benchmarks where the API smokes other models.
Lee didn't seem to care that companies like Amazon, Amazon, and Google are working on this sort of video understanding model. Most of our partners tried these big companies and came to us.
The company has raised $5 million in a seed round to take it from a prototype to a product.
The plan from here is to build out the features that have proven most useful to the people who are in the public.
All Rights Reserved © 2024




