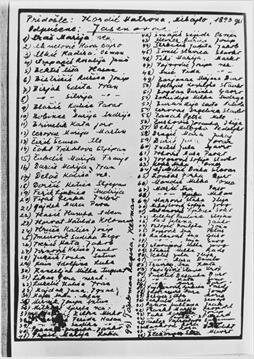
One of more than 7,000 names from American concentration camps. Holocaust Memorial Museum. This is a handwritten listing of women from Croatia and Serbia who were deported at Jasenovac. Credit: United States Holocaust Memorial MuseumMelkior Ornik, an aerospace engineering professor, is also a mathematician and a history buff. He believes in integrity when it involves using hard science in public discussion. He was naturally interested in a story about a couple of researchers who created a statistical method for analyzing data and used it to purportedly disprove the Holocaust victims of a Croatian concentration camp.Ornik is a professor at the University of Illinois Urbana-Champaign's Department of Aerospace Engineering. Ornik began to research the topic in detail and then used the method to re-analyze data from the United States Holocaust Memorial Museum. He then wrote a rebuttal document that refuted the findings of the researchers.Ornik's reply is published in the same journal that the original article. According to Ornik, the editor requested that he include answers to possible questions other scientists might have after they had read his paper. The journal added a note to the original article, stating that it did not endorse or support the views of the authors. They also recommended Ornik's paper.Ornik stated that scientists and engineers have a responsibility to correct flawed or faulty science. It takes so much effort to convince policymakers and the public to believe science. When a math expert claims they have proof, it gives credence to the argument. It's bad for science and bad for society when they claim to be false. Scientists must challenge any false findings that they discover.Ornik says that some people believe that concentration camps didn't exist, were not used to murder people, or that the numbers of victims are significantly exaggerated. The claims are not supported by the vast amount of evidence and data available to historians.Ornik stated that it was historical for the original paper's authors to claim they had mathematical proof that the camp list was faked. Although I believe that some damage has been done, I felt the need for public disclosure regarding the assumptions, inaccuracies and misuse of the museum data I discovered in my original research.Ornik replied to the paper that he presented a new method for identifying anomalies using a set of histograms. Ornik stated that he did not dispute the merits and only applied it to Jasenovac's concentration camp.Comparison of three models that were derived from the original outlier identification method and one that was derived from it. The original model lacks a theoretical foundation due to its inapplicability to the dataset. The original model is less biased in size and produces opposing results. Three alternatives models are available. Credit: Melkior OrnikOrnik was suspicious of the conclusions of the paper because the researchers suggested in one case that a smaller victim list naturally has a lower outlier score. However, they compared scores across victims list sizes to conclude that the one relating to Jasenovac, the largest, was problematic."I began to investigate if there was a bias in the size of the lists and if they were more likely to flag a list as problematic than others. Ornik stated that they were, contrary to the authors' claims. When their method is applied, the larger lists are more likely than the smaller ones to be considered problematic.Ornik, who uses similar statistical analysis for aerospace applications, explained why their statistical argument didn't work.When you are looking at data, which is a collection or anything, and trying to find an outliersomething different, you need to assume that all data comes from the same source. Consider a list of victims sorted by their birth year. This would give you a graph showing the ages of each individual. Let's say 10 percent of the population is older than 70. This distribution would not be true for a list with deported children for example. That list is, by definition structurally, different. It's also different from a list that includes everyone with an identity card. Only people who aren't children are eligible for identity cards. These lists were compiled from many sources, including lists of children, people getting married, and lists of prisoners. They are not the same distribution.Ornik also stated that duplicate lists were not treated as separate lists in their original paper. This meant that roughly 67 percent of their total database was actually sub-lists from the larger list.Ornik stated that the Holocaust Museum's 7,000+ lists are not curated. For example, two lists contain the exact same data. One is in Cyrillic while the other uses the Latin alphabet. They treated them as separate lists. Although there are many lists with the same name, it is impossible to determine if they are related or if they are two people who were born on the exact same day. You would still need to access the original historical data to remove the most serious errors.IEEE Access published both the original paper as well as Ornik's paper, Comment on TVOR: Finding Discrete Total Varation Outliers among Histograms."Melkior Ornik comments on TVOR: Finding Discrete Tolerances Among Histograms," IEEE Access (2021). Melkior Ornik, Comment: "TVOR" (2021). DOI: 10.109/ACCESS.2021.3082900University of Illinois Grainger College of Engineering




